삽입 정렬(insertion sort)은 어떤 데이터를 특정 위치에 삽입하는 방식으로 정렬이 이뤄진다. 특징은 다음과 같다.
- 삽입 정렬은 두 번째 데이터부터 시작
- 해당 인덱스(key 값) 앞에 있는 데이터(B)부터 비교해서 key 값이 더 작으면, B 값을 뒤 인덱스로 복사
- 이를 key 값이 더 큰 데이터를 만날 때까지 반복, 그리고 큰 데이터를 만난 위치 바로 뒤에 key 값을 이동
직접 눈으로 보면 더 이해가 쉽다: https://visualgo.net/en/sorting
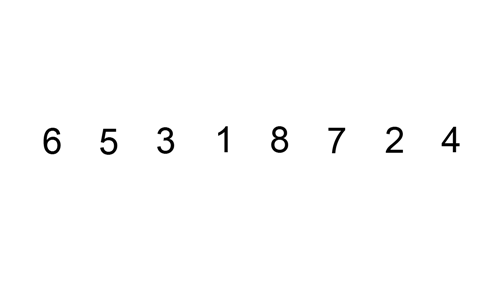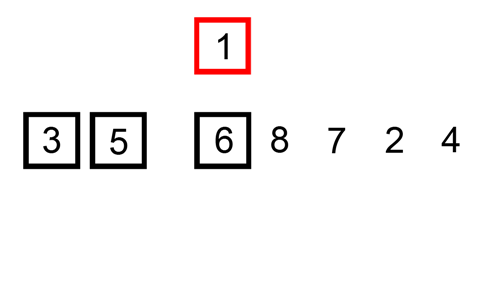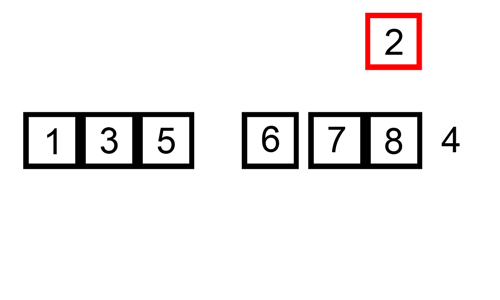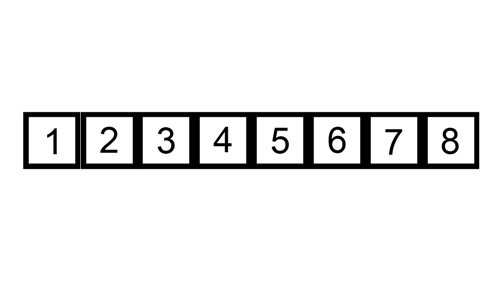
데이터가 4개일 때를 예시로 들어 로직을 이해해보겠다. (데이터 개수에 따라 복잡도가 떨어지는 것은 아니므로)
ex) data_list = [9, 3, 2, 5]
- 처음 한 번 실행하면, key 값은 9, 인덱스(0) - 1은 0보다 작으므로 끝: [9, 3, 2, 5]
- 두 번째 실행하면, key 값은 3이다. 9보다 3이 작으므로 자리 바꾸고 끝: [3, 9, 2, 5]
- 세 번째 실행하면, key 값은 2이다. 9보다 2가 작으므로 자리 바꾸고, 다시 3보다 2가 작으므로 끝: [2, 3, 9, 5]
- 네 번째 실행하면, key 값은 5이다. 9보다 5가 작으므로 자리 바꾸고, 3보다는 5가 크므로 끝: [2, 3, 5, 9]
알고리즘을 구현해보면,
- for stand in range(len(data_list))로 반복
- key = data_list[stand]
- for num in range(stand, 0, -1) 반복
- 내부 반복문 안에서 data_list[stand] < data_list[num - 1] 이면,
- data_list[num - 1], data_list[num] = data_list[num], data_list[num - 1]
이 순서로 코드를 작성하면 된다.
def insertion_sort(data):
for index in range(len(data) - 1):
for index2 in range(index + 1, 0, -1): # index + 1 부터 0 까지 1 씩 줄이면서 반복
if data[index2] < data[index2 - 1]:
data[index2], data[index2 - 1] = data[index2 - 1], data[index2] # swap
else:
break
return data
위 코드를 테스트 해보면,
import random
data_list = random.sample(range(30), 10)
print(insertion_sort(data_list))

이렇게 잘 정렬되어 출력되는 것을 알 수 있다.
삽입 정렬의 알고리즘을 분석해보면, 반복문이 두 개이므로 버블 정렬과 동일하게 시간 복잡도는 O(n^2)이다. 최악의 경우 n * (n - 1) / 2 이다.
완전 정렬이 되어 있는 상태라면 최선은 O(n)이다.
[참고자료]
패스트캠퍼스 개발자 취업 합격 패스 With 코딩테스트, 기술면접 초격차 패키지 Online 강의자료
'Data Structure & Algorithm' 카테고리의 다른 글
| 선택 정렬 (Selection Sort) (0) | 2023.01.19 |
|---|---|
| 버블 정렬 (Bubble Sort) (0) | 2023.01.17 |
| 힙 (Heap) (3) (0) | 2023.01.10 |
| 힙 (Heap) (2) (1) | 2023.01.06 |
| 힙 (Heap) (0) | 2023.01.06 |



